Product
Highlights
A lifesaver in emergencies
Built for instrumentation (bad at everything else)
Stores recent raw samples for adhoc analysis
Prunes data by time and memory constraints
Emphasizes a comparative analysis workflow
Self Hosted & Open Source Software
Snorkel (the frontend)
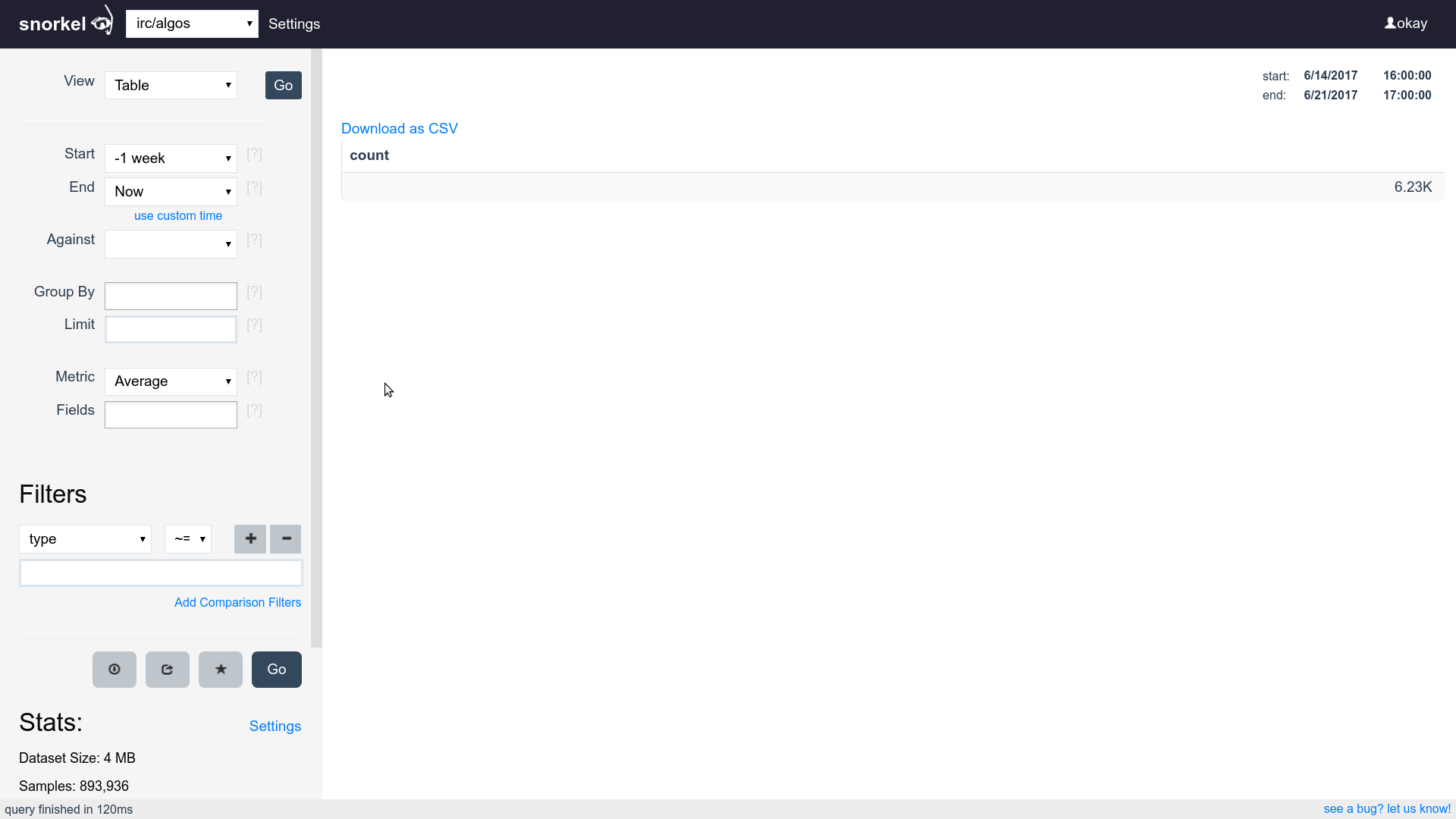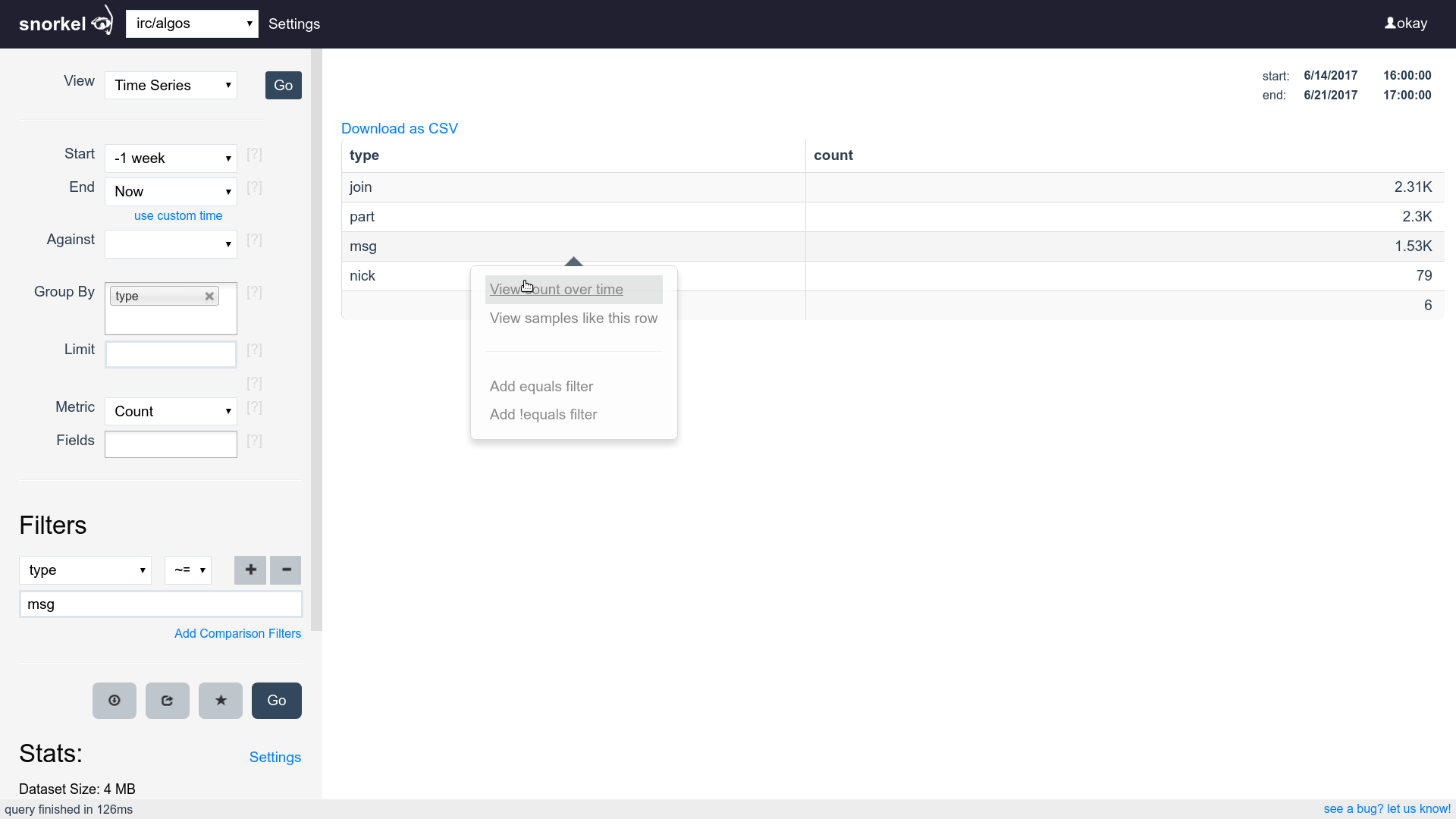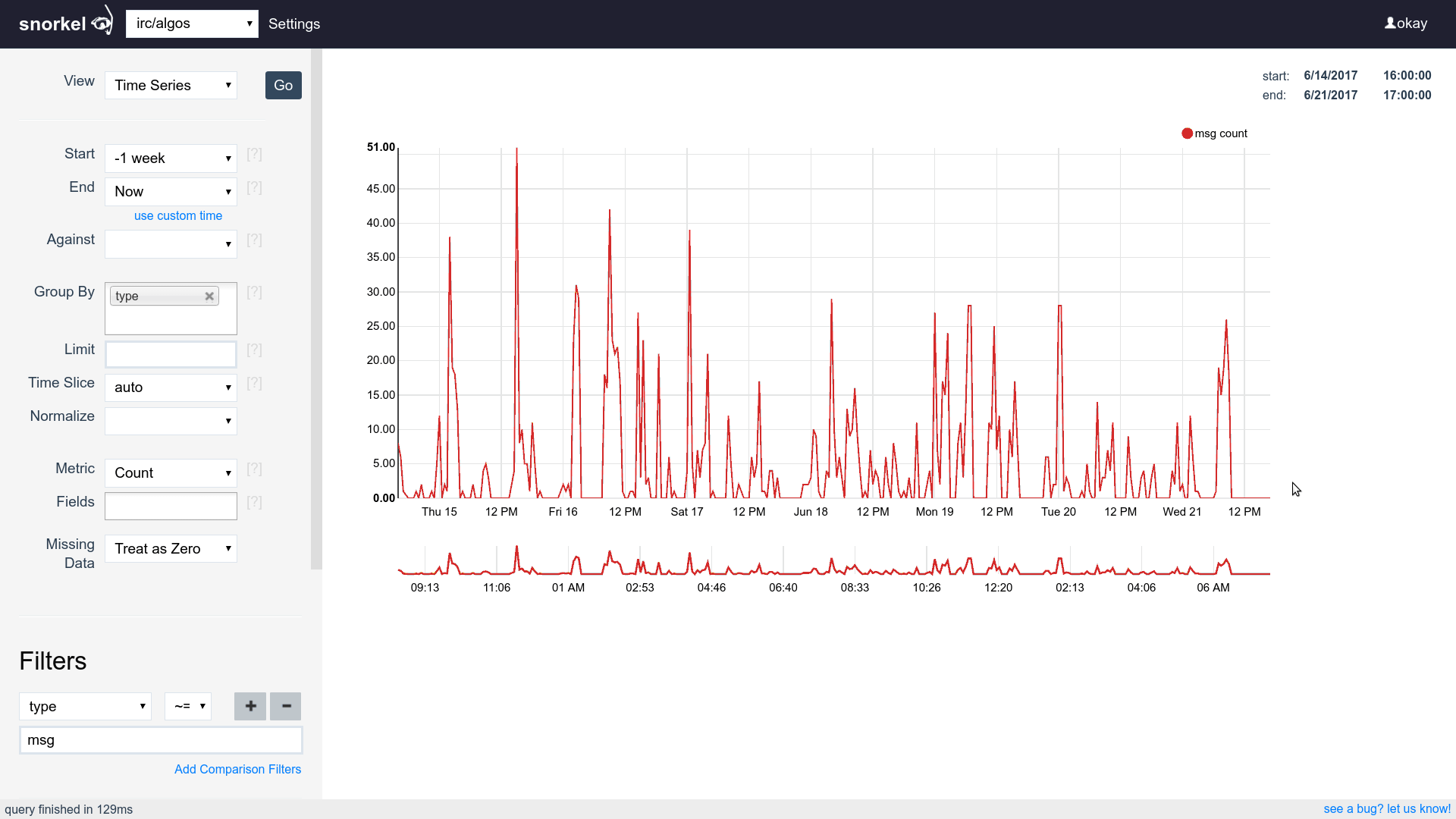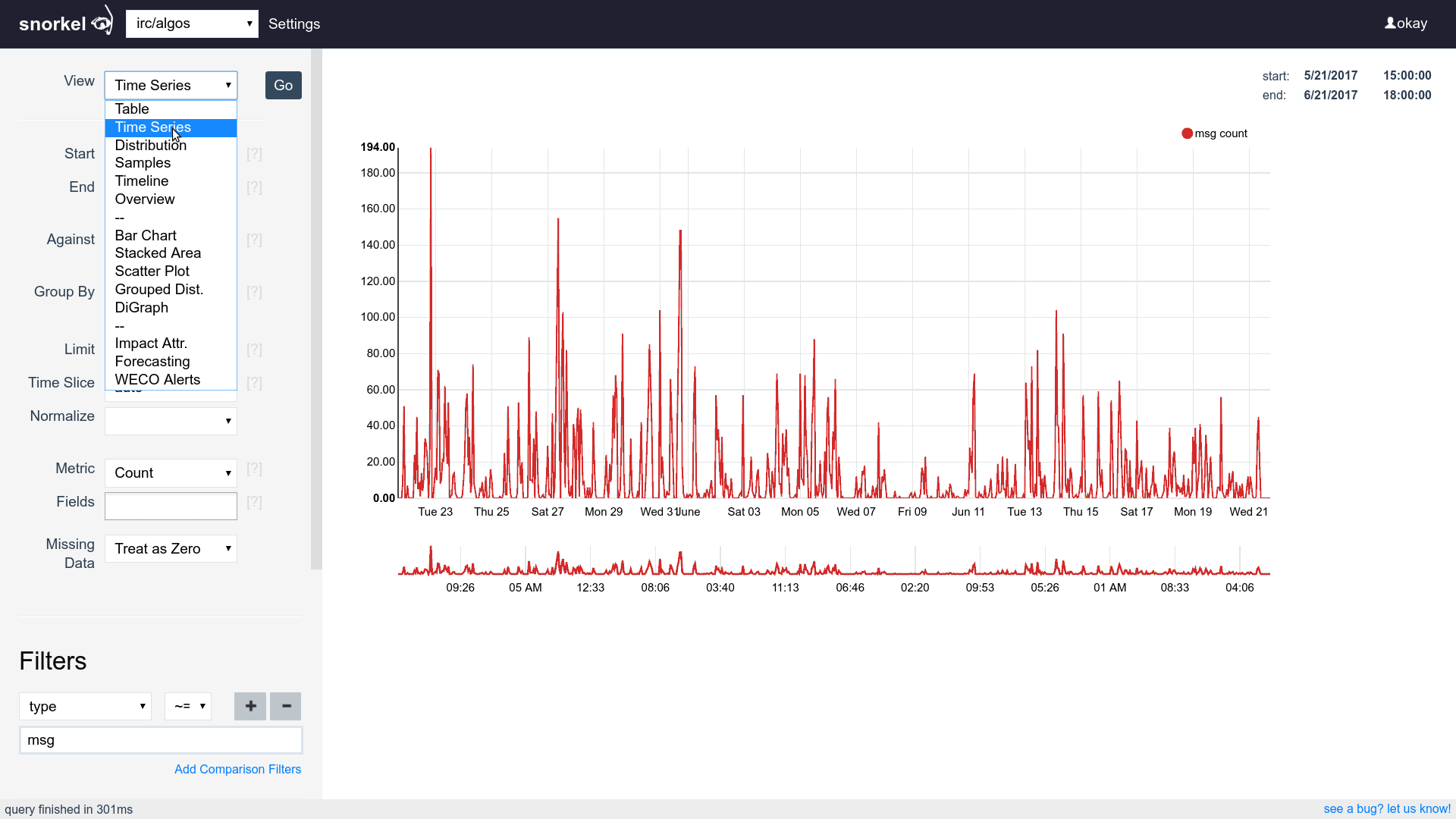
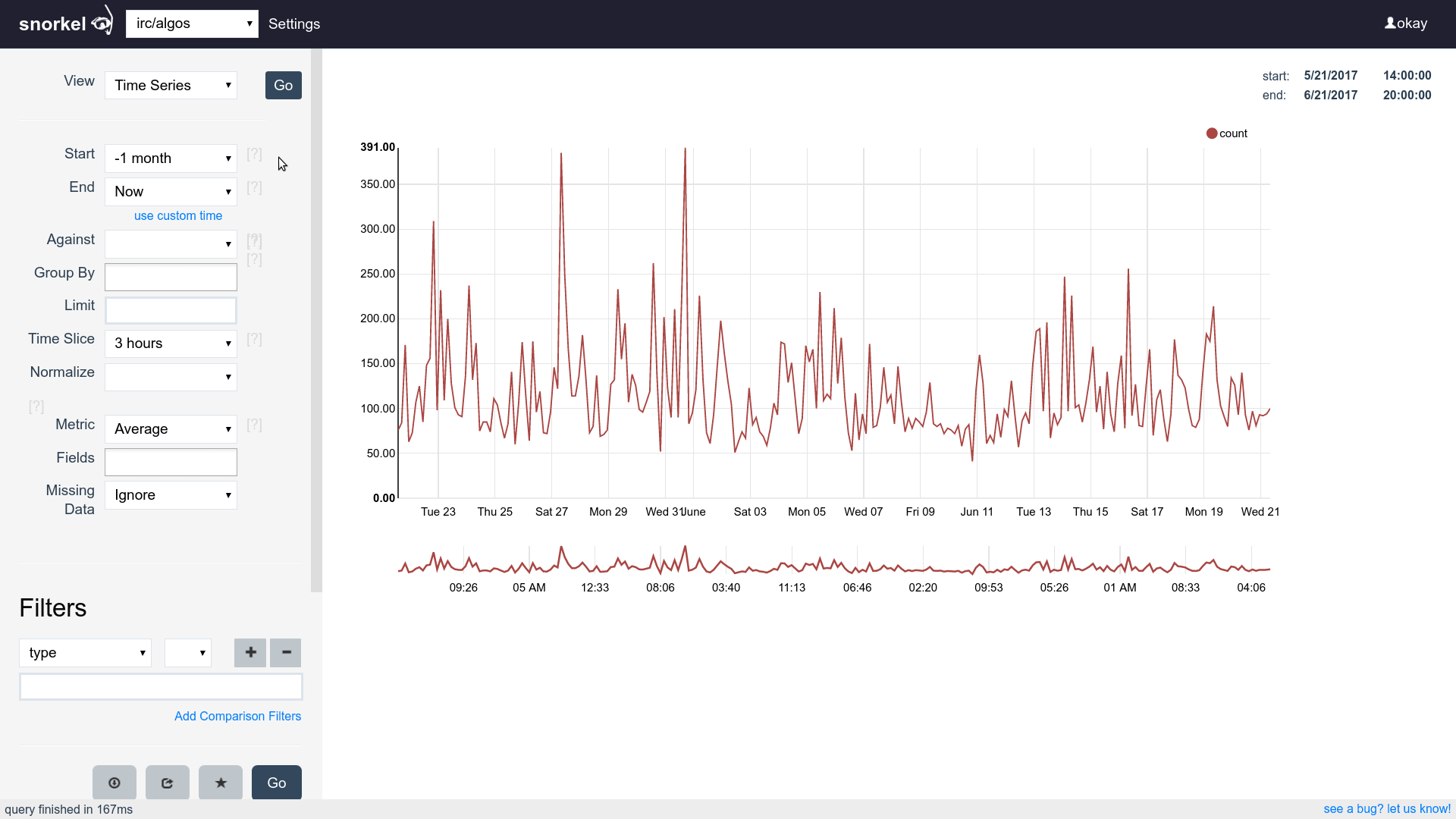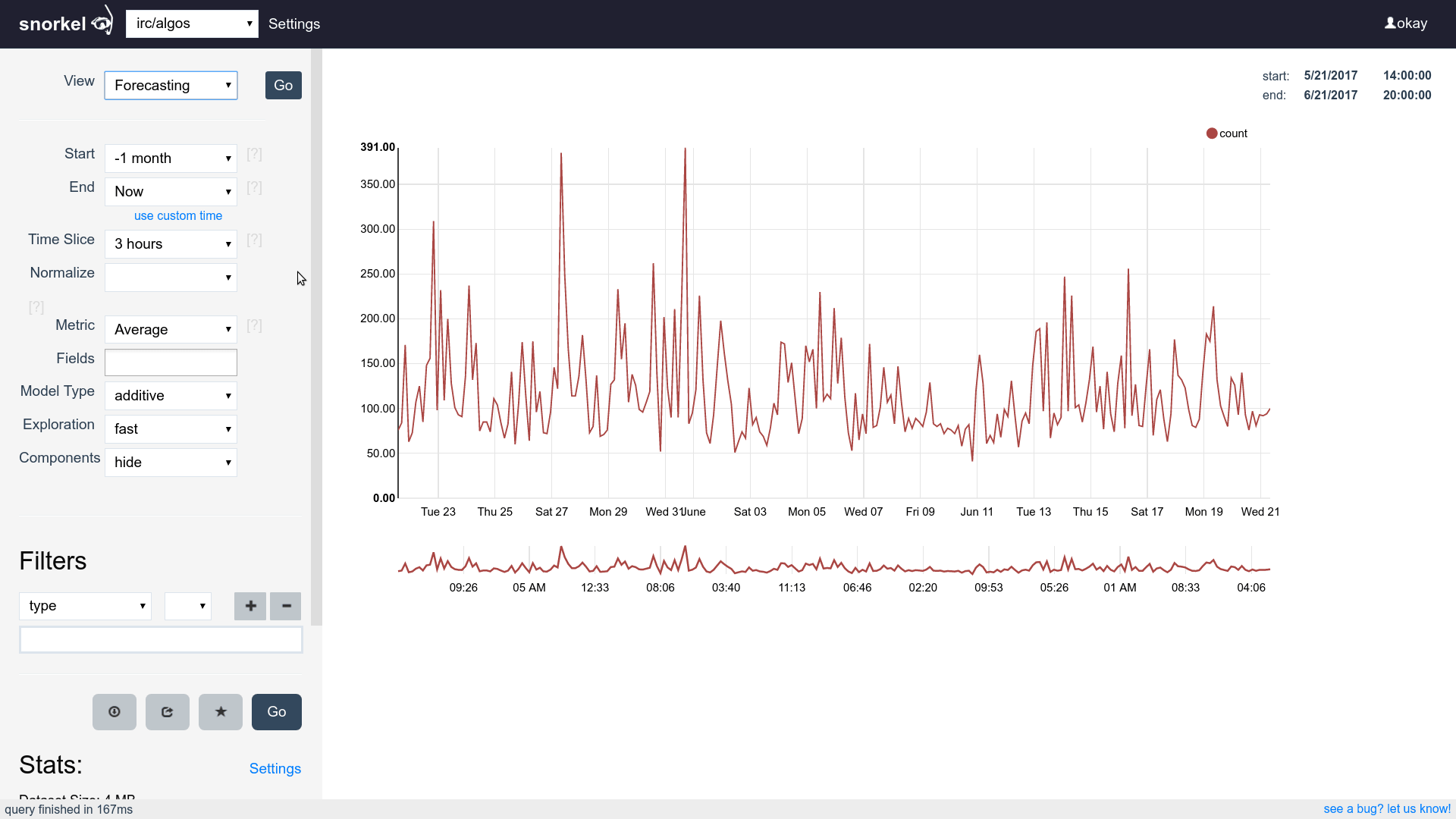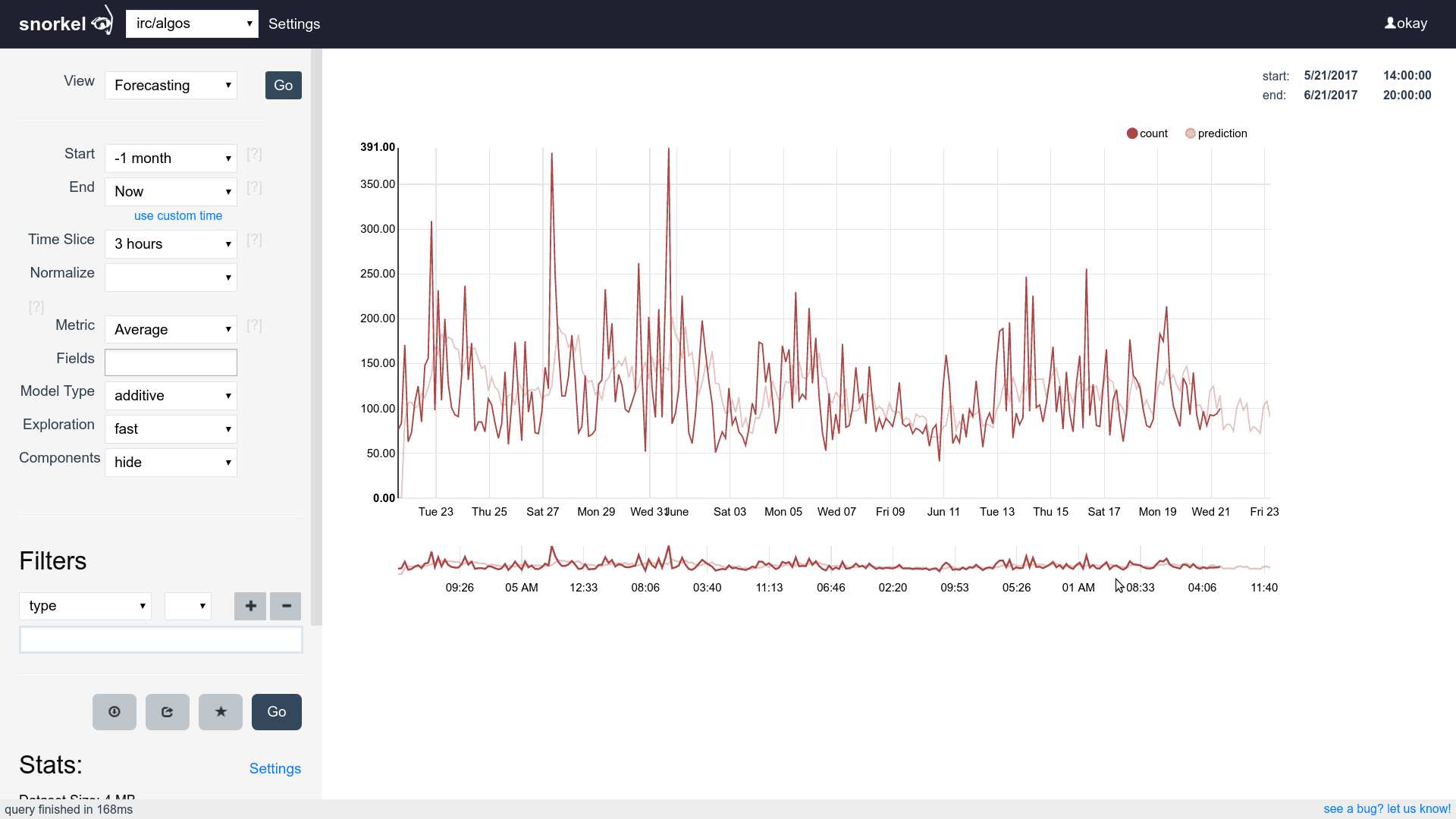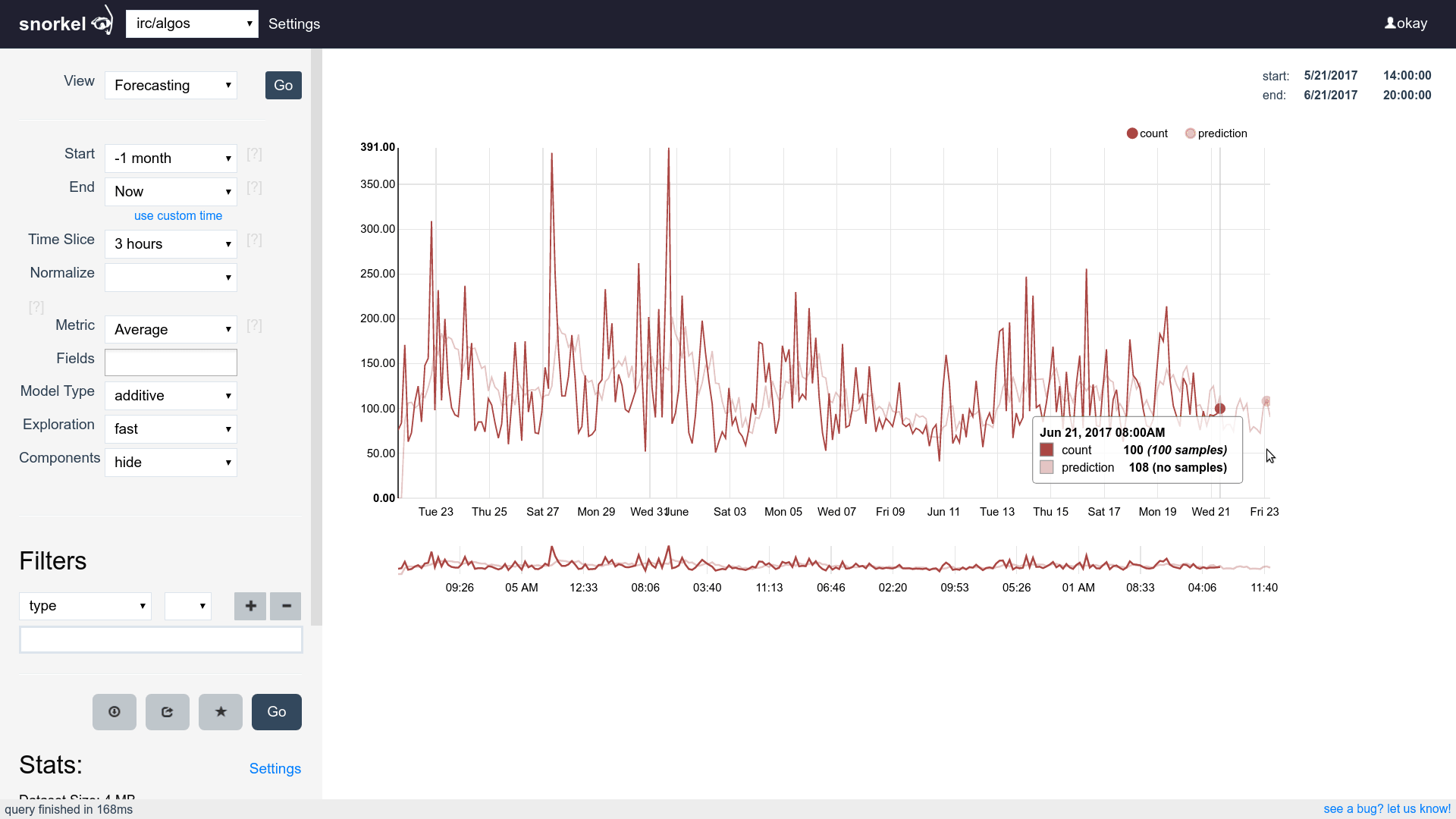
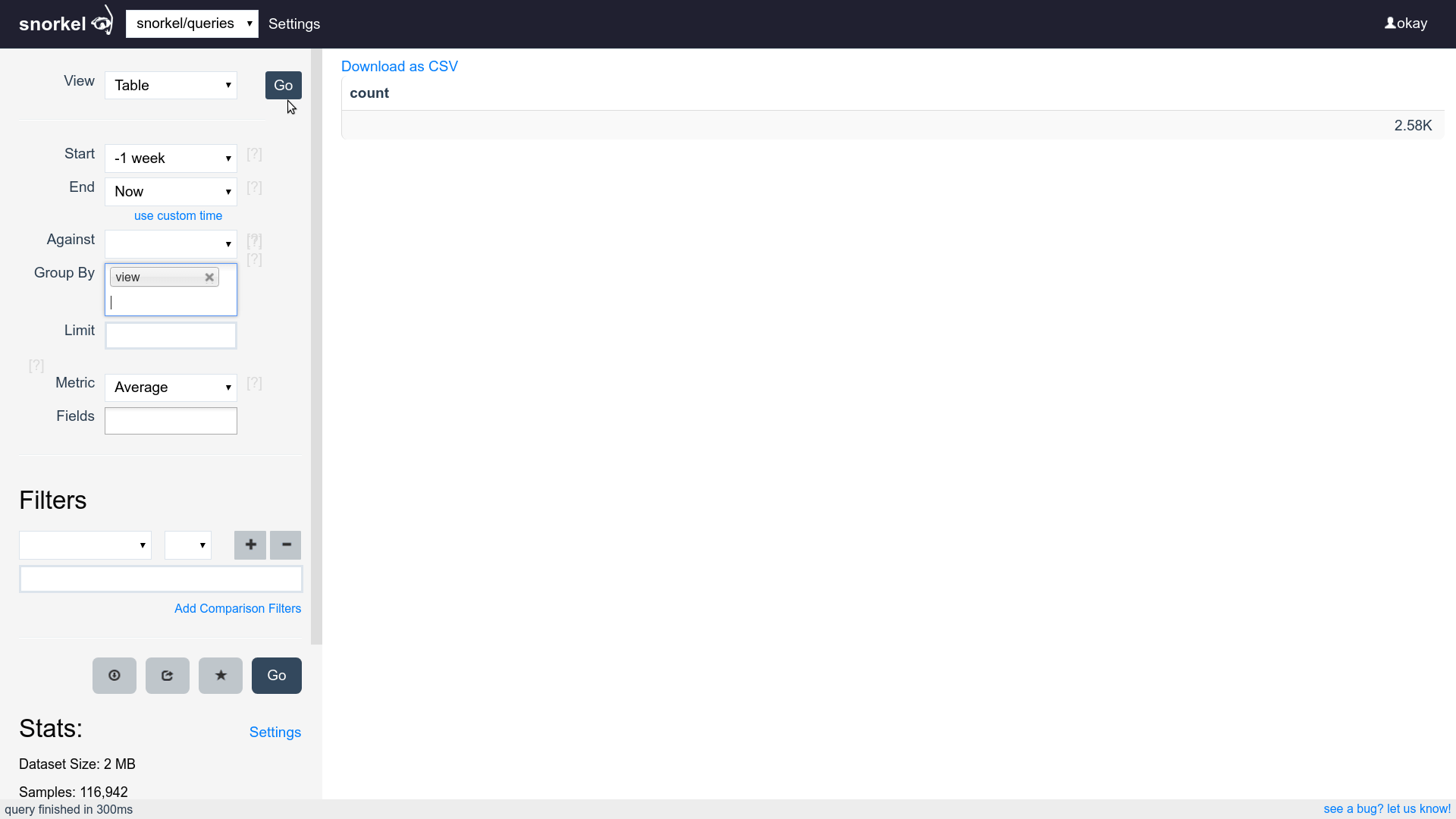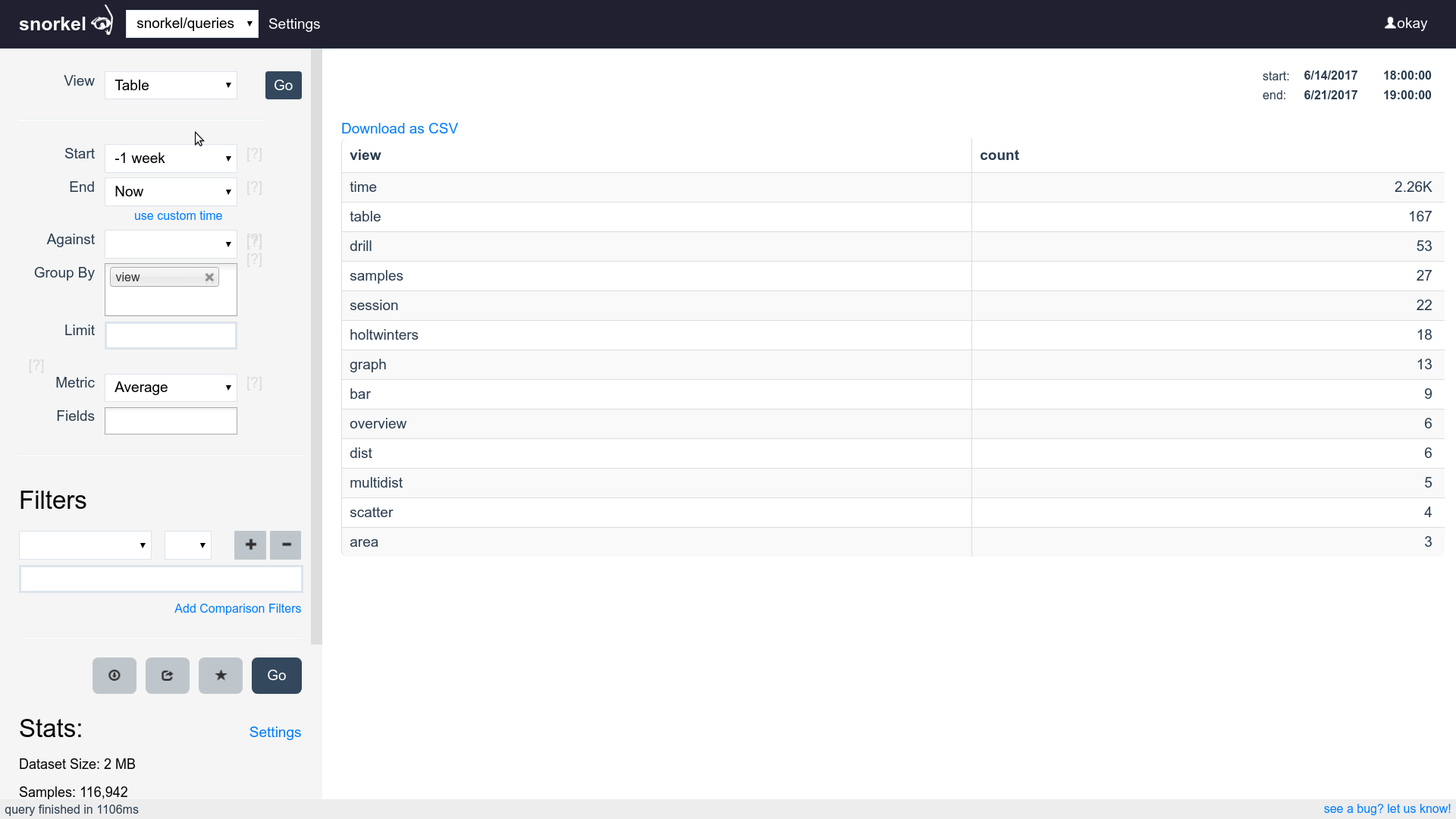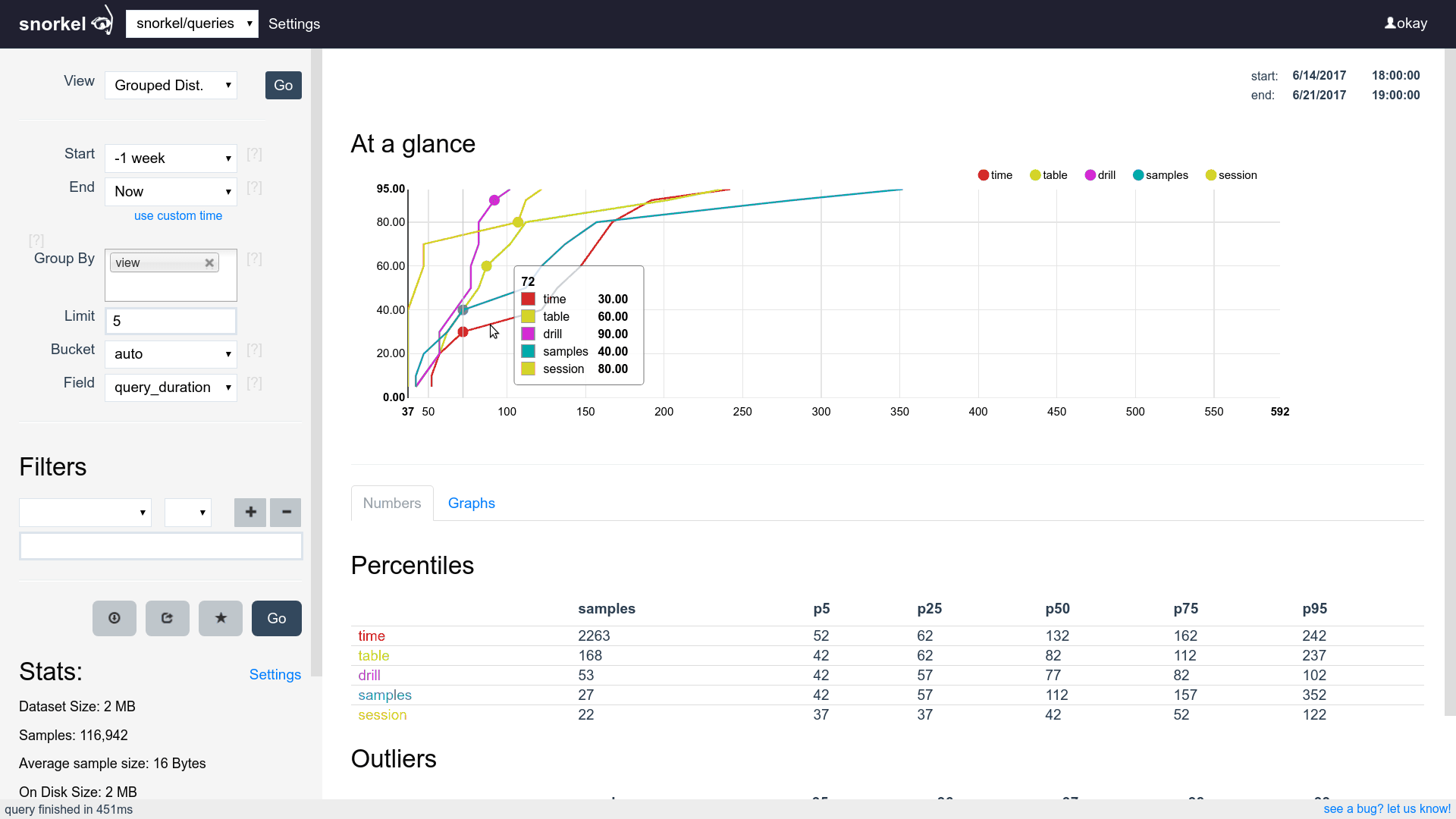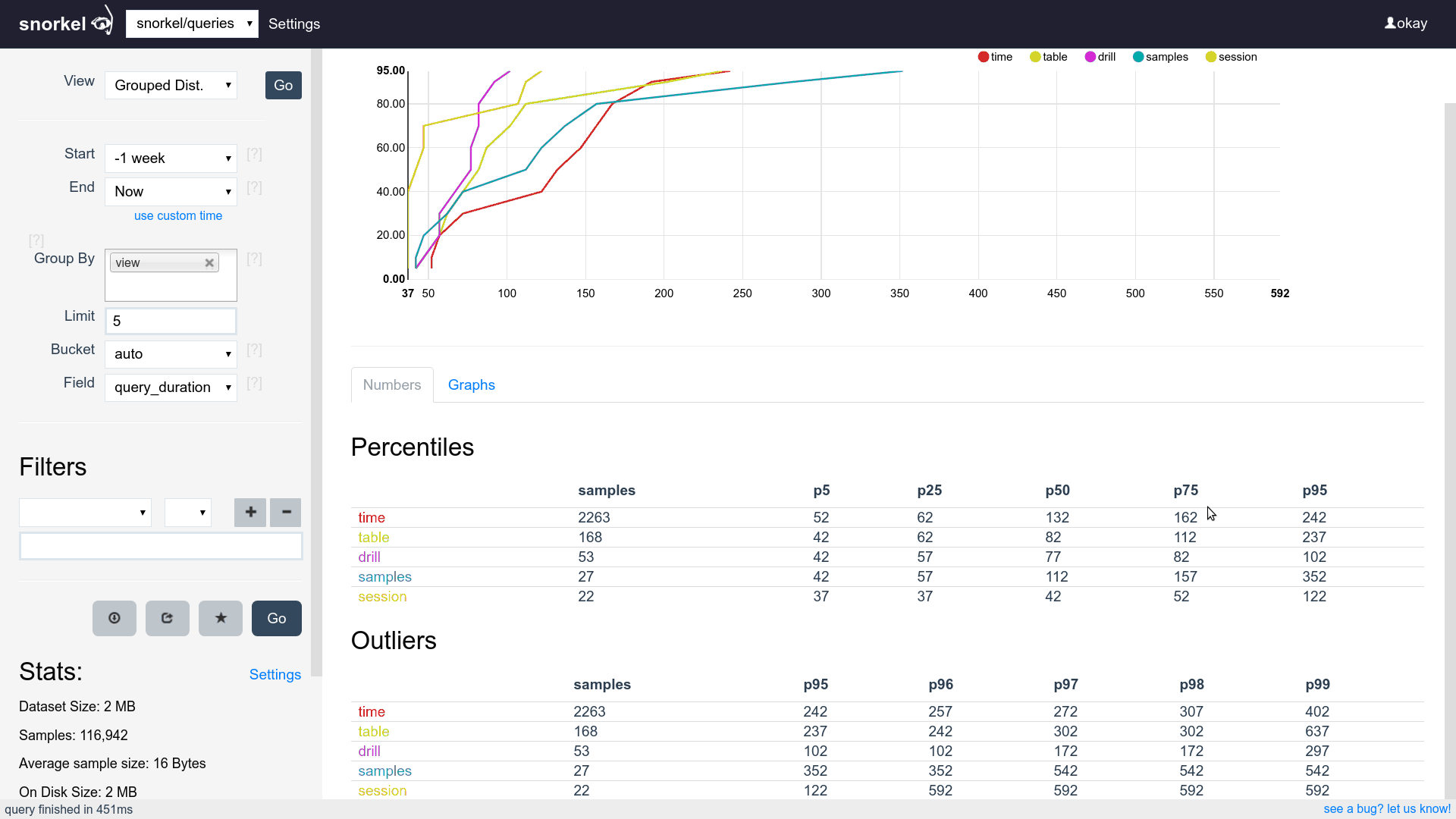
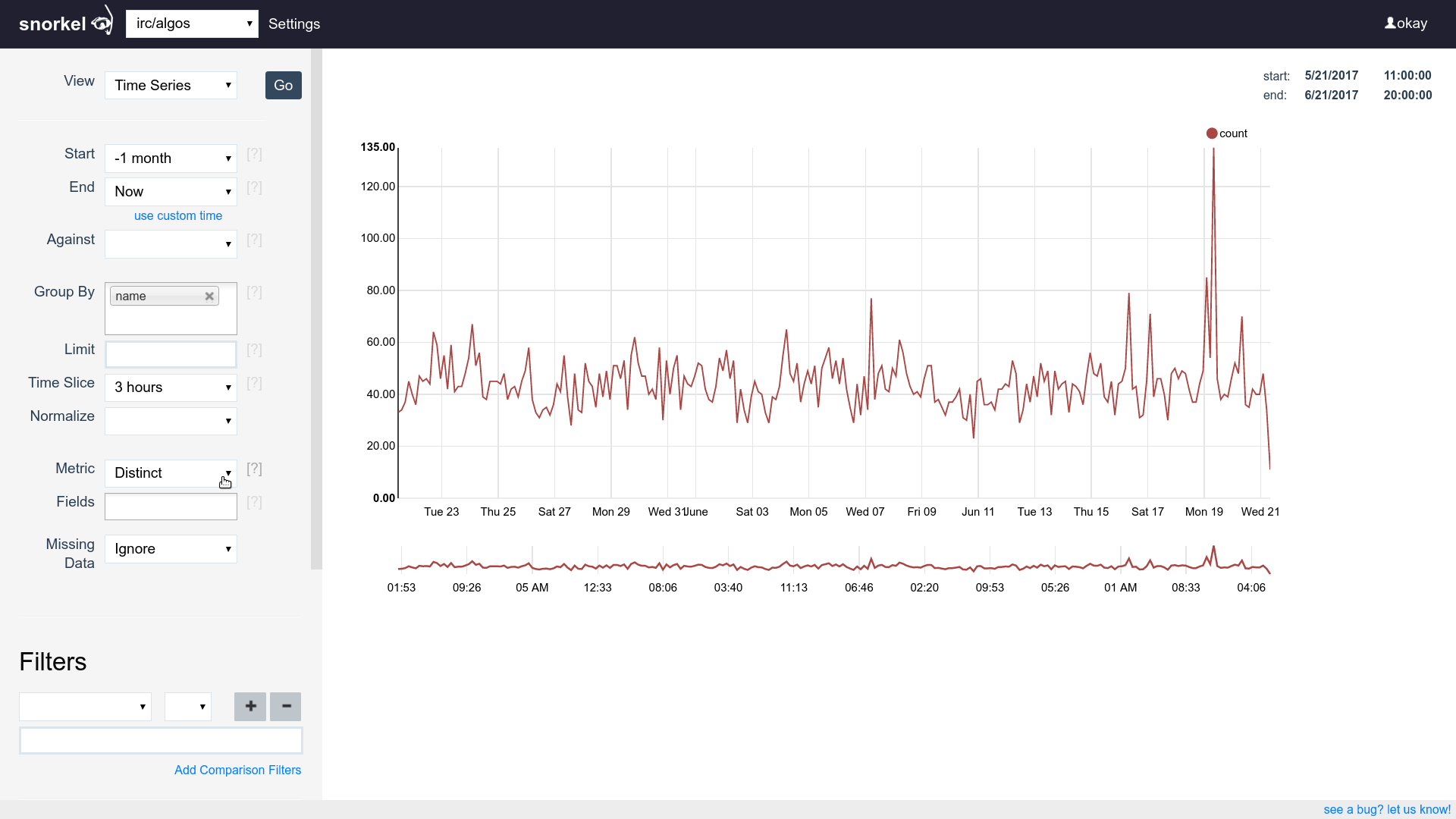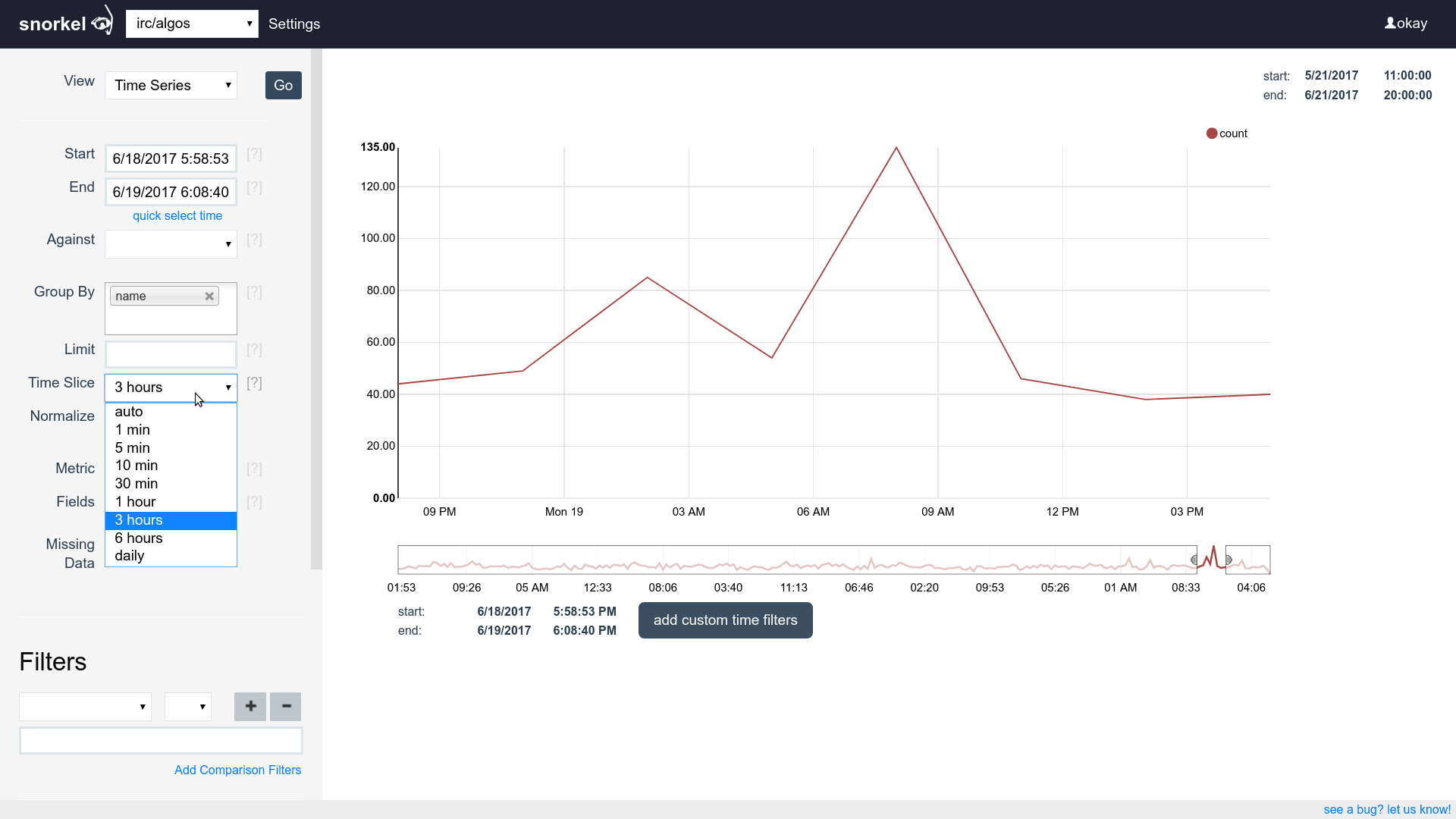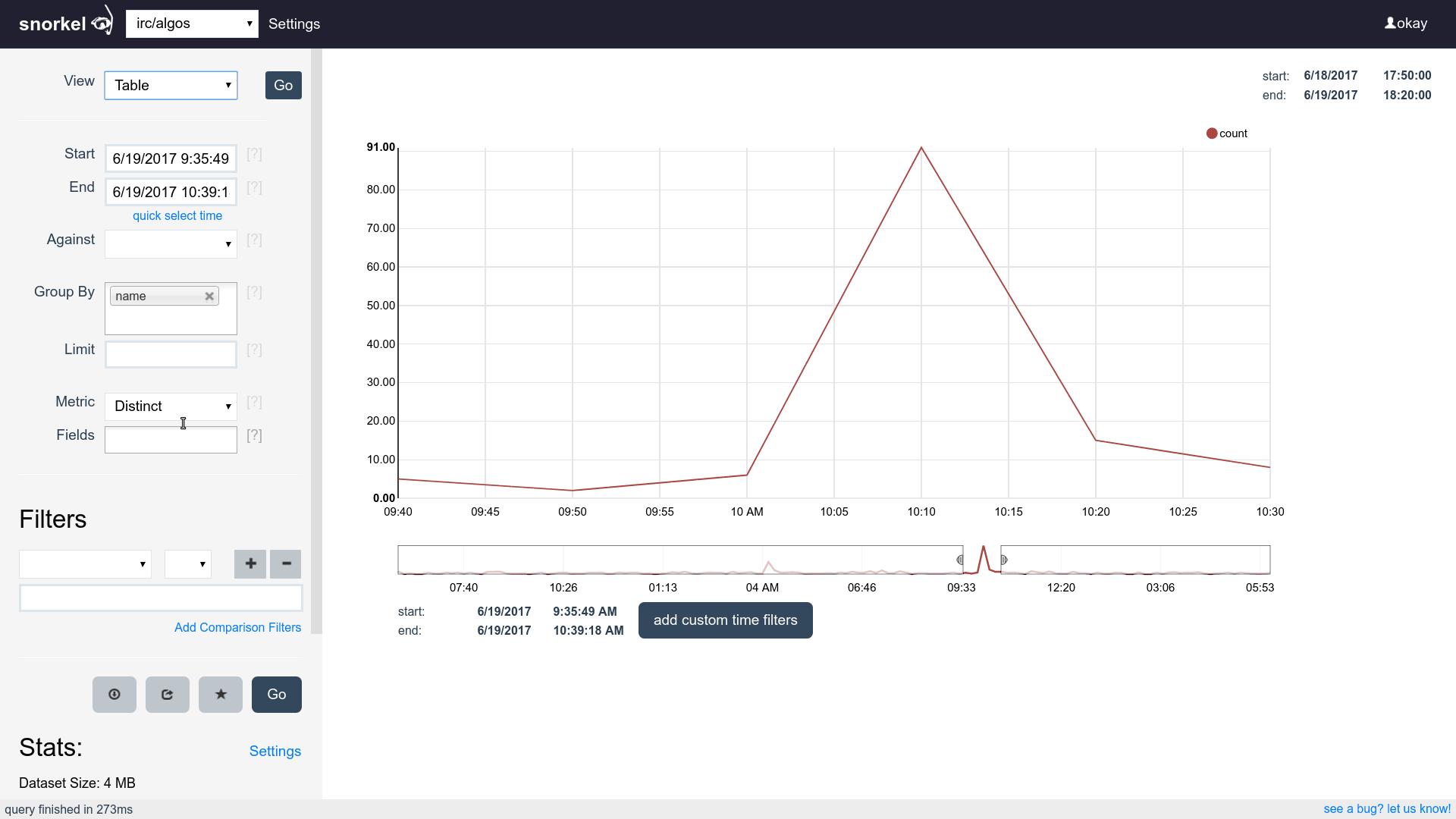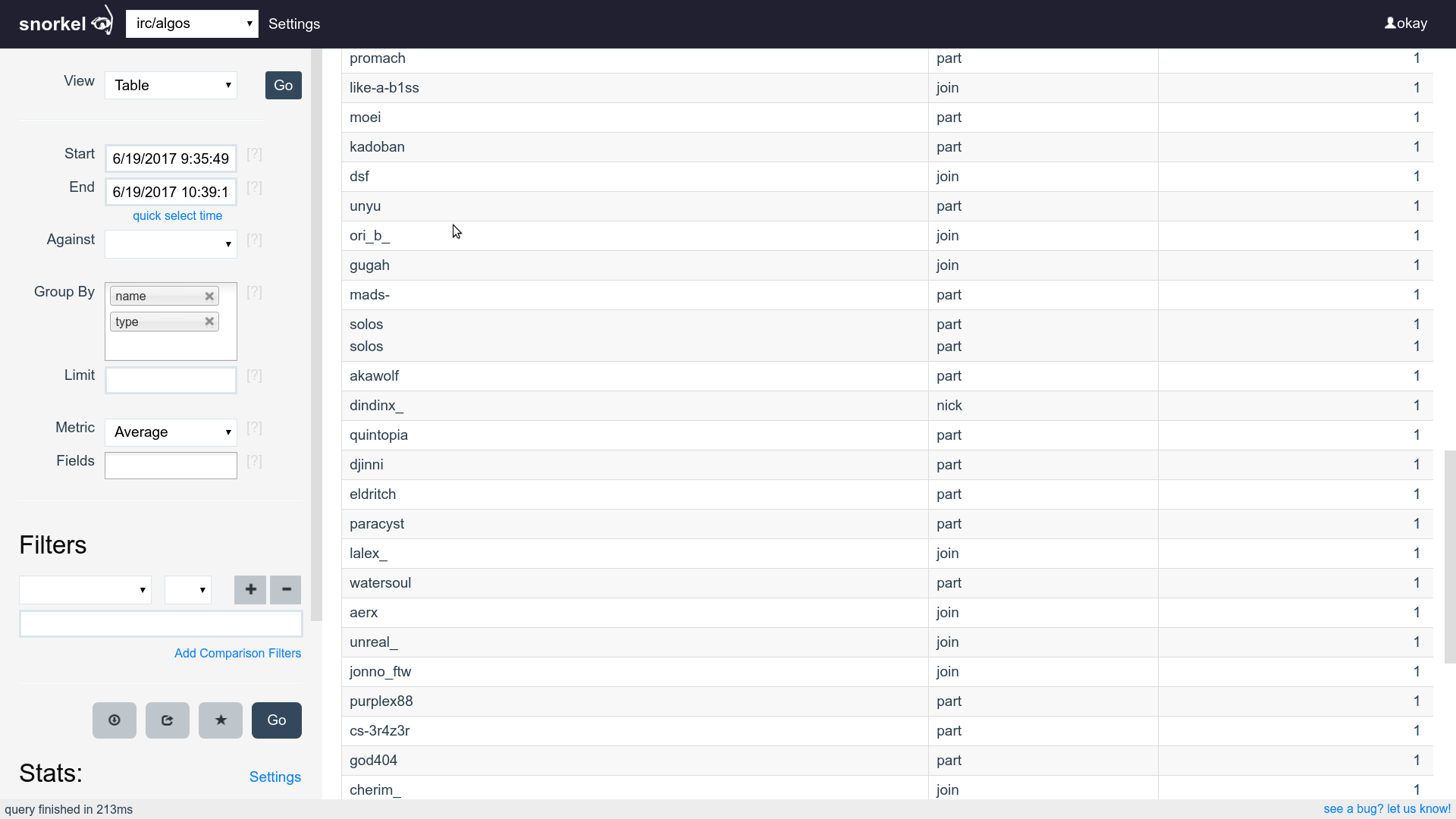
Query & Visualization Builder
Built for ease of querying
Many visualizations, one dataset
Comparison queries are first class
Common controls across visualizations
Supports filtering, grouping and aggregating
Supports time series, tables and histograms
Flip between differents views of the same data easily
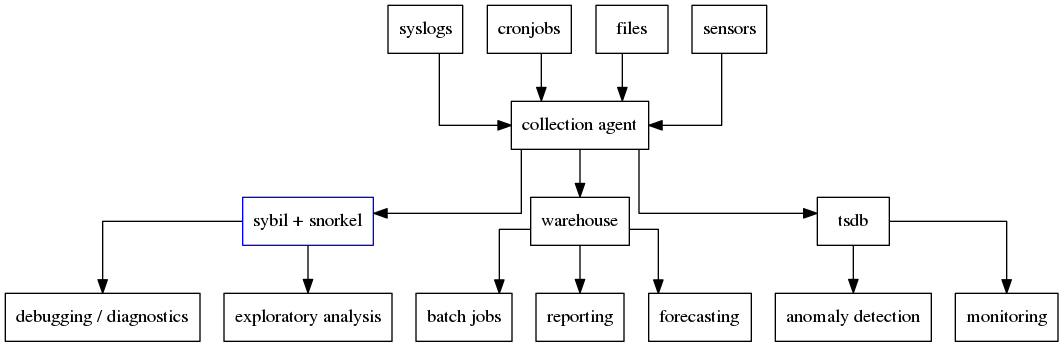
Sybil (the backend)
Append only OLAP for JSON data
Built for ease of ingestion
Data organized in datasets
Limit table size by time and memory
No table creation step: log and query immediately
Better compression with columnar storage
High performance with multi-threaded aggregation
Queries executed on the fly: full table scans only
Use cases
Organizational
A/B Testing
Firefighting
Bug Tracking
Perf Experiments
Deploy Monitoring
Personal
IoT & HW Sensors
Browser Usage
Web Analytics
Fitness & Health
Tradeoffs
Pros
Good for about 10mm - 30mm rows per query
Performs well as a firefighting tool
Good for digging into anomalies
Get an intuitive feeling for datasets
Cons
>100mm samples is not recommended
No SQL syntax
No joins, no updates
Is not a replacement for monitoring with TSDBs
No support for engagement or retention queries
Comparisons
vs Time Series DBs
Good for monitoring & long term trends
Products
InfluxDB
Graphite
RRDTool
Prometheus
TSDB Pros
Very fast queries and throughput
Has good UI and dashboarding
Long term data retention
TSDB Cons
No Datasets, top level keys instead
Single numeric quantity per key
Only supports time series queries
Does not store raw data
Bad at digging into anomalies
vs Column Stores
Good with analytics, logs, etc
Products
Interana
Memsql
Druid
Presto
ElasticSearch
Big Table
Clickhouse
Column Store Pros
Sharded, supports massive data!
Supports JOINS and advanced queries
Supports engagement queries
Built in SQL query engine
Is a full fledged DB
Column Store Cons
Hard to setup / Requires a cluster
Tables require creation step
Requires schema maintenance
vs Traditional DBs
Good with user & app data, etc
Products
Mysql
Postgres
Vertica
Rethinkdb
SQL server
RDBMS Pros
Battle tested, very robust
Supports JOINs and advanced queries
Supports engagement queries
RDBMS Cons
Tables require creation step
Requires schema maintenance
Single threaded aggregations
Row store architecture (bad for full table scans / arbitrary filters)